
The quality of the datasets we use for training machine learning models is an often-discussed subject. I wanted to test the popular saying “garbage in, garbage out” by making a few toy scripts to explore the effect of dataset poisoning. For this, I use some popular datasets provided by Keras: MNIST, fashion-MNIST, CIFAR10 and CIFAR100. All four consist of images, and the model will perform classification.
The experiment shows that the model used is surprisingly robust even when it mislabels more than half of the dataset. Additionally, the same percentage of bad data has a greater effect on a smaller dataset.
The code can be found on my Github.
Poisoning the dataset
I train multiple models on varying proportions of bad data all the way from 0% to 100%. For the first round of experiments, I used a random wrong class as labels for the mislabeled data. Seeing the surprisingly high accuracies produced, I wondered what the difference would be if the errors were more systematic. The “biased” models mislabel data by always using the first available wrong class.
Training
The focus of the experiment is on the obtained accuracy relative to data, so I have chosen a simple sequential convolutional neural network as the model. Since the datasets have different difficulties, the model will perform worse on the harder ones.
I train a different set of models on a subset of the training datasets to investigate whether that changes anything. The intuition is that the effect of data poisoning is more pronounced on a smaller dataset.
The models train until their validation accuracy stops improving in over 10 epochs. Additionally, the learning rate reduces after 5 epochs of no improvement.
Evaluation
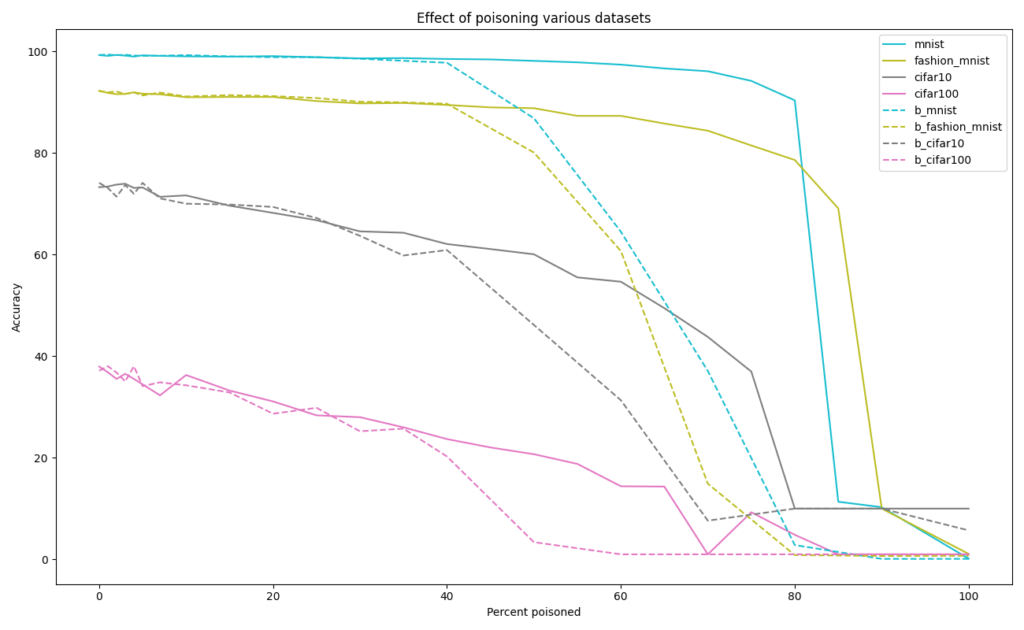
I evaluated the models using the validation datasets provided, kept unmodified. Training on the full datasets shows the easy MNIST dataset maintaining a very high accuracy even with 80% of the data randomly mislabeled. However, the more complex datasets such as CIFAR-100 quickly dropped in accuracy even with small quantities of bad data. Biasing the wrong labels to almost always be a single class caused accuracy to start dropping quicker, but the models were still robust up to 40% poisoning compared to their random counterparts.
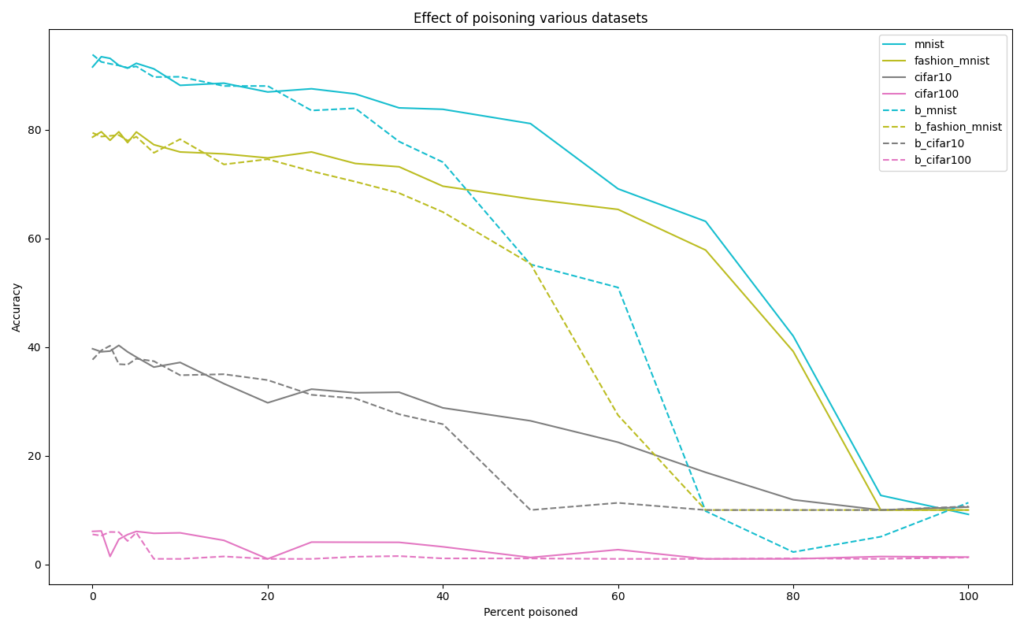
I trained the models on the first 1,000 items from the training set, as this is a more reasonable quantity of labelled data to own compared to 60,000 (MNIST), 50,000 (CIFAR). In this case, the wrong labels affect the accuracy significantly earlier. The CIFAR100 model should be disregarded as it was unable to train with ~10 input images per class, even with no poisoning.
Conclusion
The machine learning model is surprisingly robust to wrong data, as it shows the ability to continue learning even when most of the data is wrong. While some bad data is almost unavoidable in a real-world scenario, it’s also interesting to observe that worse, but more data can in some situations be preferable to better, but less.
Future work:
- I used a batch size of 256 for training. Would a more standard batch size of 32 worsen training?
- How would poisoning the validation datasets change the plots?
- Would a larger model show different results?